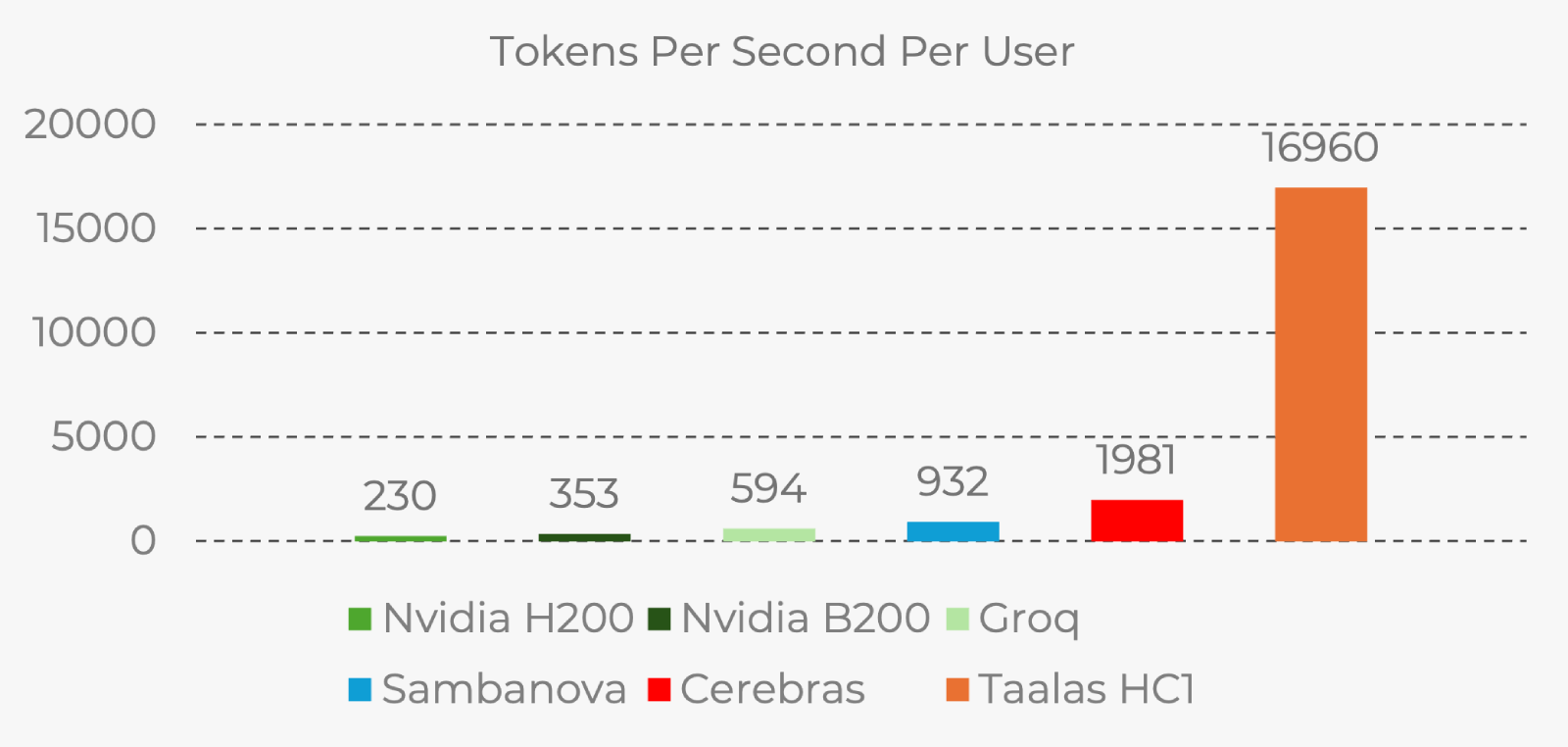
When I viewed the Taalas demo on chatjimmy.ai, I was left speechless. I had to double-check that the content wasn’t gibberish, and I tried multiple prompts. Each response came in at ~0.03 seconds, streaming at somewhere between 15k and 17k tokens a second! Seventeen thousand!
The company’s blog post is a must-read. If you are a casual observer of the AI space and didn’t quite grok what the post is going on about, I’ll give you the abridged version and my thoughts on it.
The pre-Taalas World
The way your AI inference is normally served is through GPUs. These massive hunks of silicon use a lot of electricity (~700W), and cost a lot of money to produce. NVIDIA’s H100 GPU retails at $30,000.
This state-of-the-art chip will take a few seconds to respond to your prompt. The main bottleneck is the round-trip between the memory and compute. The part that stores the data (the model’s weights), and the part that performs the compute are physically separate pieces of the chip’s hardware. This is a fundamental design trade-off. While the industry has innovated on this setup with HBM (High Bandwidth Memory), there is still a limit to how fast GPUs can be for this use-case.
Taalas’s Radical Idea
Since the company’s founders are from ex-Yugoslavia, I can feel confident in speculating that their company’s name references the word talas, which means “wave.” And this is indeed a new wave of AI infrastructure.
Their new chips are purpose-built. They’re what you would call application-specific integrated circuits (ASICs), and they come “hard-coded”. By which, I mean, that the AI model’s weights are directly wired into the silicon during the manufacturing stage. They claim that this eliminates the memory-compute divide entirely. And I believe them—the demo is amazing; they can’t fake that.
The HC1 Chip is their first product, and it’s what powers the demo chat app. The model that’s running on the chip is Llama 3.1 8B.
The Limits
So, what’s the trade-off? There’s always a trade-off, right? You may have already sensed this coming, but once you put something directly into silicon, well, that’s it. Their chips are not general purpose. An NVIDIA chip might run Opus 4.6 today, but it can easily be repurposed for Opus 5 when it comes out. In contrast, the HC1 that delivered us this demo will always run the Llama model that was imprinted into it.
Taalas also says that they need time to figure out how to imprint each new model that comes out. Right now, that time seems to be 8 weeks until they can ship it on the chip. There’s limit to the model sizes they’re able to add on the HC1, but HC2 is in the works, and will support a wider range.
Here’s the bad news for Taalas: new models are currently coming out rapidly, which makes the HC1 seem like a fast-depreciating asset. After 2 years, you’ll be left with a bunch of chips serving fast compute for models that nobody wants, and you’ll have to buy new ones to get the new models running. Yet, the fast-depreciating nature might not be a big deal at all. If Taalas’s post it to be believed, they have cut the cost of production by 20x and are using 10x less energy to keep it running.
Implications
The tech is real, but we don’t know yet whether the financials of the production and operation of these chips are exactly as Taalas describes it. If yes, then as soon as they hit the mass market, inference costs are going to start dropping like flies. Providers of open-weight models are already struggling to procure GPUs, so this will be an immediate purchase. Expect inference costs in 2027/2028 to experience a big drop.
A few days in my post about the state of AI bubble, I wrote that the dropping inference prices of open-weight models are a major threat for the current economic model of Big Tech.
Here is a trimmed version of the cost table of the current models:
| Model | Price per 1M input tokens | Price per 1M output tokens |
|---|---|---|
| Claude Opus 4.6 | $5 | $25 |
| Gemini Pro 3.1 | $2 | $12 |
| GPT 5.2 Codex | $1.75 | $14 |
| Kimi K2.5 | $0.23 | $3 |
Imagine if Kimi K.25 was even cheaper, while being 10x faster? Ouch. At some point, the advantages of the other models won’t be so big, because the user could just retry a task instantly.
Of course, nothing stops the big players from being the first to adopt this. Maybe NVIDIA is already working on something like it. Maybe Amazon or Google are about to give Taalas an offer they can’t refuse. No clue.
Stay optimistic,
—Filip