I’ve been using Kimi K2.5 for coding via OpenCode’s generous Free Trial period, and for other ad hoc tasks via T3 Chat. It’s become my favorite model across all activities, surpassing anything from Anthropic, OpenAI, and friends.
That doesn’t mean it is it the best. By all benchmarks, it certainly is not. But something about the way I personally use AI seems to gel well with the model, and I feel really productive with it. Similarly, for non-coding, I really enjoy the way it responds (“the vibe”), and how it doesn’t veer into obvious sycophancy. I noticed this with Kimi K2 last years, and now it’s even better.
Let’s look at some examples.
Benchmarks
First the facts. Let’s start with the Good:
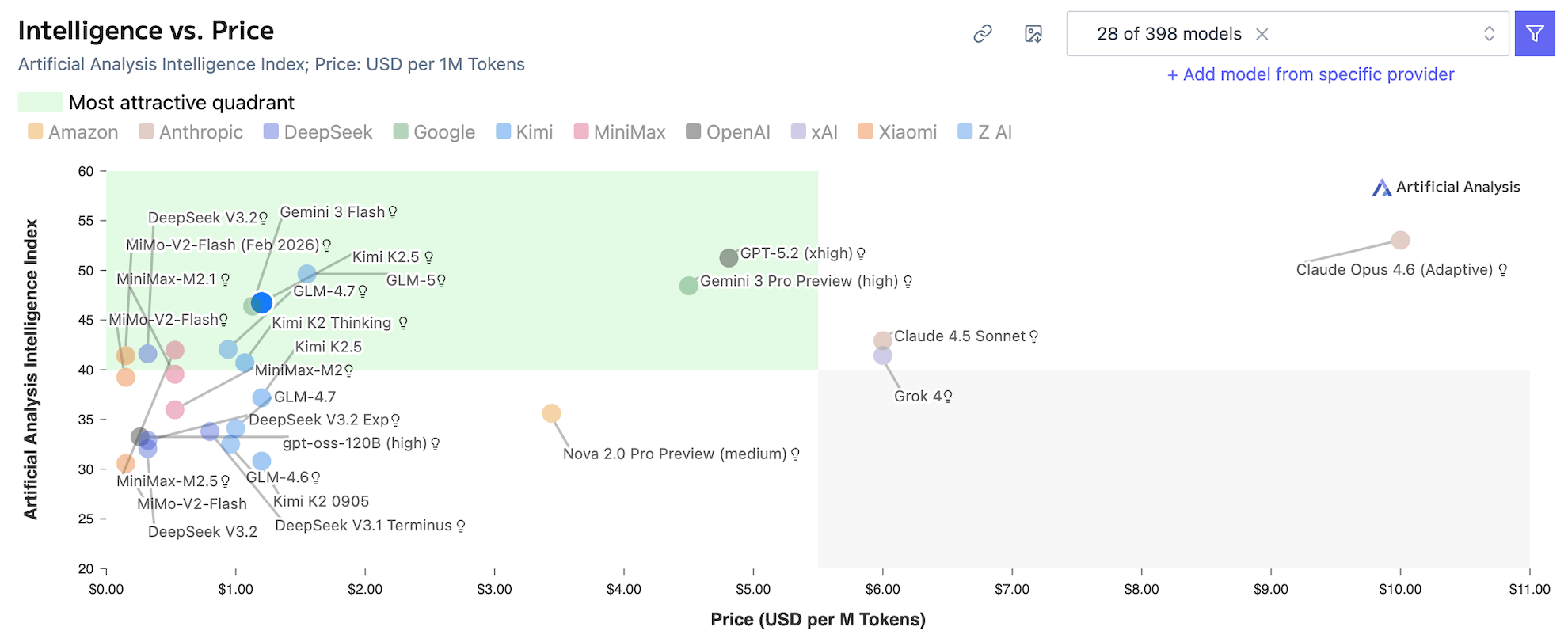
Then, the Bad & the Ugly:
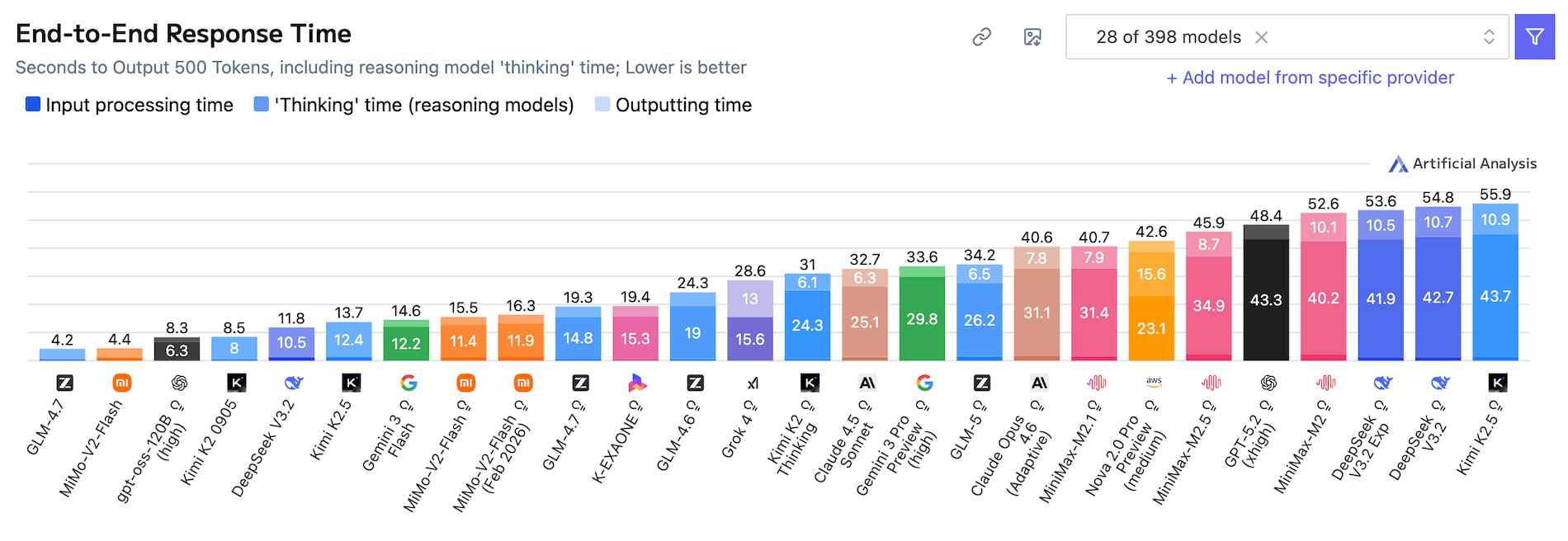
Now for the anecdotal experience.
Tough Love + Backbone
I’m currently writing a book. A piece of noir + urban fantasy fiction, which is an interesting sell. I am also—as you may know—not a published author, and thus an amateur.
I’ve used T3 Chat to try all the major, flagship models as critique partners. Almost none of them offered me any “tough love” on the default, naïve prompt. They were over-supportive, and quick to focus on the good sides of my manuscript. To be fair, I didn’t want them to brutalize me either, but I expected some semblance of balance. When I asked for harsher feedback, they would provide it, of course, but if I pushed back, then they would retreat. Clear sycophancy; no backbone.
Kimi K2 was a novel experience. It dished our brutal critique, while realistically highlighting the good sides, constructively: “Here is what you should double-down on.” If I pushed back, it would not always give up. But here was the part that really impressed me—I shared an idea of what I am planning to do in the next chapter, and it pushed back. It stood its ground on what it believed was the strength of the story (atmosphere, the protagonist’s cynicism), and advised me not to do it. All the other models were quick to tell me how good my idea was!
After using Kimi K2.5 as a critique partner, I’m observing that this behavior is still present. Context retrieval and reasoning also feel better—I feel comfortable saying that, as my manuscript is large, and thus full of “need in a haystack” problems.
Coding
I use LLMs for coding in two ways:
- Amazon Kiro (yes, really) + Cline, both with Anthropic’s latest Sonnet and Opus models.
- OpenCode + Cline, with all other models. (Trying new things, so to speak.)
Opus remains the king for me. But I have to say that Kimi K2.5 fits really well into the category of “best model to use for personal projects.” The primary hallmarks of this category are: 1) the need for something cheap, and 2) application on smaller, newer codebases.
What it gets right:
- Good at planning (also, uses clarifying questions wisely)
- Efficient tool-calling
- Following the “spirit” of the request, and not overdoing things. (Though this may just be OpenCode’s harness?)
- Price/quality ratio is superb
What could be better:
- Speed
- Speed, but even more
I don’t know if it will stay my favorite for long. Minimax M2.5 is a serious contender. I also need to check on Z.ai’s GLM-5.
I can’t wait for this all to be irrelevant in 6 weeks.
Anyway, remember to stay hydrated,
—Filip