The tech industry is obsessed with complicating things. Take caching as an example—too many articles jump straight to Redis. Scaling up? Add Redis. Performance issues? Add Redis. Already have Redis? Add more nodes. Doing a system design interview? Don’t forget to pencil in a box for Redis or you won’t pass the interview.
In practice, you can get away without any Redis-like cache for quite a while. That’s what I want to explore today. I don’t want people wondering “how do I add Redis?” until they have some actual intuition that it will solve a real problem.
What Problem Are You Solving?
Before picking a tool, it helps to be explicit about why you’re caching at all. Usually it’s one (or more) of:
- reducing latency
- reducing CPU load on your data source (DB, another API, etc.)
- avoiding repeated expensive computation
If none of these are painful yet, you probably don’t need caching at all. If you can prove through load testing that it still wouldn’t be a problem after you scale by 10x, then you can forget about it completely.
If the pain shows itself, the next question is not Redis vs. something else. It’s: Where should the cache live? Let’s think through that question from the perspective of a couple of different system designs.
What Can Go Wrong?
Let’s start with the simplest system: a single application instance talking to a database. (I promise we will discuss Lambdas and serverless later.)
users <---> app <---> databaseWhat are the signs that things are going wrong? Consider some possible scenarios:
- End-to-end request latency is growing, or is already too high (track your
p95). The app and database are mostly okay on CPU and memory. - The database is constantly under heavy load, while the app is mostly idle.
- The app’s CPU or memory usage is constantly high, while the database is mostly idle.
Only one of these three is a very clear sign that a cache might help; the other two require more nuance and better instrumentation. Your golden metrics will always be:
- end-to-end latency (start with p95)
- network latency between users/app and app/database
- task processing latency of your app and your database
When you have all these, you can break down your end-to-end latency into stages and identify your levers. For example, a lot of systems do not optimize how much data they are sending over the wire, or the cost of serializing and deserializing it. I see so many apps where the API returns a list of 20+ objects, each 5 KB in size, only to render a table with 3 fields and a navigation link. This kind of data hoarding introduces a heavy cost at every layer: more network latency, more DB read load, and more processing time for serialization. It also hits both memory and CPU usage.
There is so much stuff you might be able to optimize before you add anything to this beautifully simple architecture.
But Don’t Allow It Go Wrong
I am not saying you should wait for things to go wrong before you optimize.
This is where load testing comes into the picture, especially for products that are only launching. You should test at three levels: your current or realistically expected scale, 10x scale, and 100x scale. Then, at each step, analyze what went wrong and what levers can help. You do not have to implement all of them, because the solutions for your 100x scale problem do not need to be delivered today. But you should know what they are and how long they would take. The solutions that get you to 10x, though, might be something you want to already implement today.
And hey, if your system already has no issues handling 10x scale, then don’t waste further time on this.
Now, let’s look at three case studies that really do need caching. We’ll observe three different architectures:
- single-node
- multi-node
- serverless
Case 1: Single-node System (Underrated Sweet Spot)
Imagine that first system again, and imagine its problems spiking when you go 10x:
- growing traffic
- latency issues (DB, APIs, computation)
- plenty of available memory on the host
You look at the metrics and identify that the DB has become the bottleneck. A cache seems like the way to go. But pause there for a second. Have you verified that your application will have a good cache-hit rate? Some systems struggle here because they have a very large keyspace and a lack of trend in their usage patterns.
You could figure this out with a prototype, or by analyzing your logs across 5-10 minute windows. How often are you making a query for the same object or list? Are there any clusters? If you cached everything in one 5 minute window, how much of it would be a cache-hit in the next window? If the answers look promising, then adding a cache will look very appealing.
The next question is where the cache should live. The industry has conditioned you to think that you need to add a Redis node in front of your database, like:
users <---> app <---> redis <---> databaseYou might also have been sold on a managed Redis service, which promises to make it easy to add more Redis hosts in front of your database. But I would encourage you to step back and try just an in-memory cache in your app first. You will get:
- zero network overhead
- extremely fast lookups
- trivial implementation
- no extra infrastructure
For many systems, this is enough to significantly reduce latency, take pressure off the database, and stabilize performance to meet your 10x targets. It can be as simple as adding an LRU map, or you could take advantage of the unused disk space on your host and set up SQLite as a local cache layer. This was my motivation for creating tobolac, a local cache for Bun and Node.js that is blazing fast:
| library/key space | 1k | 10k | 100k |
|---|---|---|---|
| no-cache | 13,571 | 13,609 | 13,608 |
| node-lru | 97,498 | 93,183 | 51,928 |
| bento-multitier (redis + lru) | 105,107 | 108,851 | 74,585 |
| tobolac (sqlite + lru) | 459,531 | 376,200 | 246,387 |
I am not trying to sell you on my library. But I am trying to sell you on trying things out first and benchmarking scenarios that make sense for your system. If you can get away with something like this, it will makes your life easier and keep the architecture simple.
This is also not some fringe opinion. AWS’s excellent Caching challenges and strategies piece explicitly calls out local caches as a useful first step, and even Redis has client-side caching docs built around the idea that avoiding the network can dramatically reduce latency and backend load.
But will it still be useful if your scale increases so much that you need multiple hosts?
Case 2: Multi-host / Horizontally Scaled Systems
Let’s move to a system that’s had to scale out:
users <---> load balancers <---> app [multiple nodes] <---> databaseAt this point, an in-memory cache will likely become a problem. Not because the miss rate will necessarily increase, but because you start hitting cache invalidation and consistency bugs. Since each instance has its own cache, the data inside starts diverging quickly. Creating a DIY distributed cache invalidator is going to be a big pain. This is where Redis, or a similar system, starts to make sense. (Redis has a decent write-up on cache consistency patterns if you want a quick tour of the trade-offs.)
load balancers <-> app [multiple nodes] <-> redis/valkey [replicated or managed] <-> databaseYikes. Seems like we can’t exactly sketch it with test anymore. We are in diagram territory.
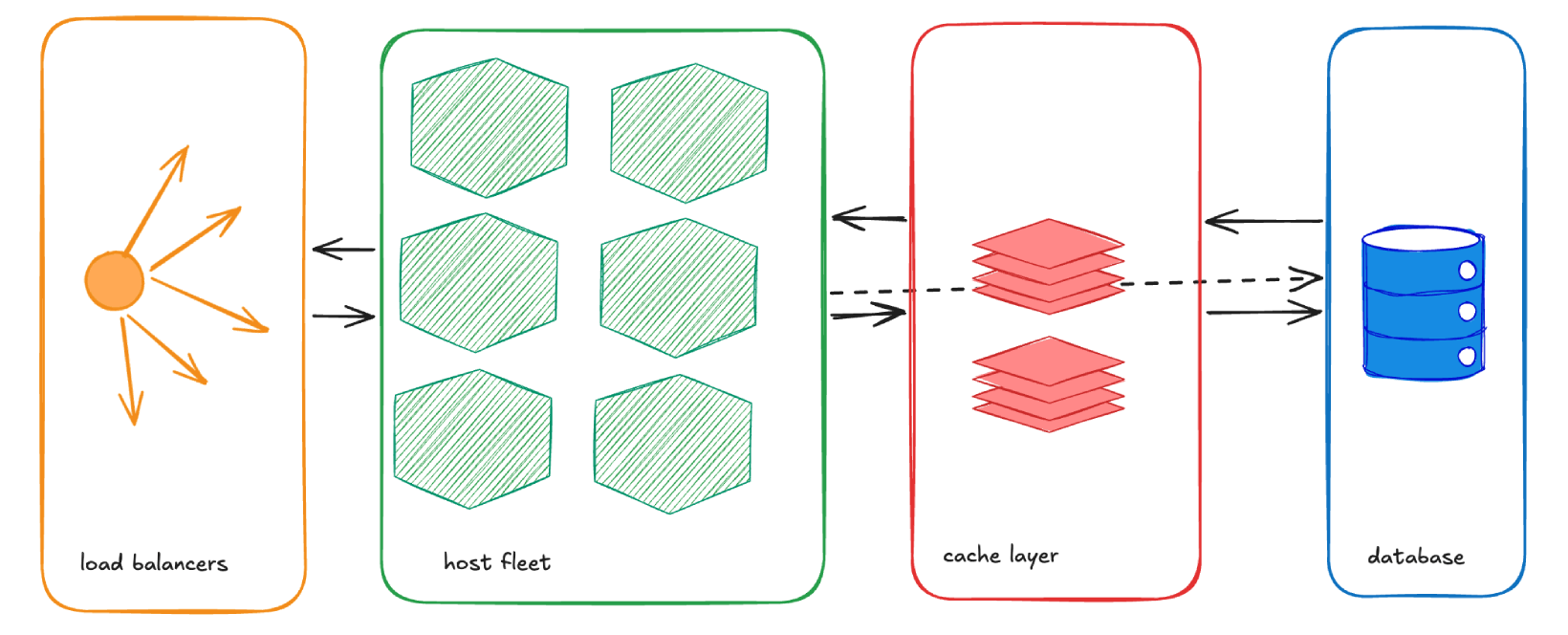
Can you get away without adding it? Maybe. If a single node could serve efficiently as a simple key/value store for all of your application nodes, then you could start there. This might work pretty well for a small fleet. But there’s a reason people quickly move past “one box running Redis” and start thinking about replication, failover, or a managed service. Your application should be resilient enough to work when the caching layer goes down, but ideally you do not want to let it get to that point. Once multiple app nodes depend on a shared cache, availability and operational simplicity start to matter a lot more.
A Rare Case for In-Memory on Multi-Host Systems
There is one exception to the above analysis, where you do not need to think about a separate cache and can still use in-memory caching reliably. That case is when you are building a system that allows for reliable routing of user groups.
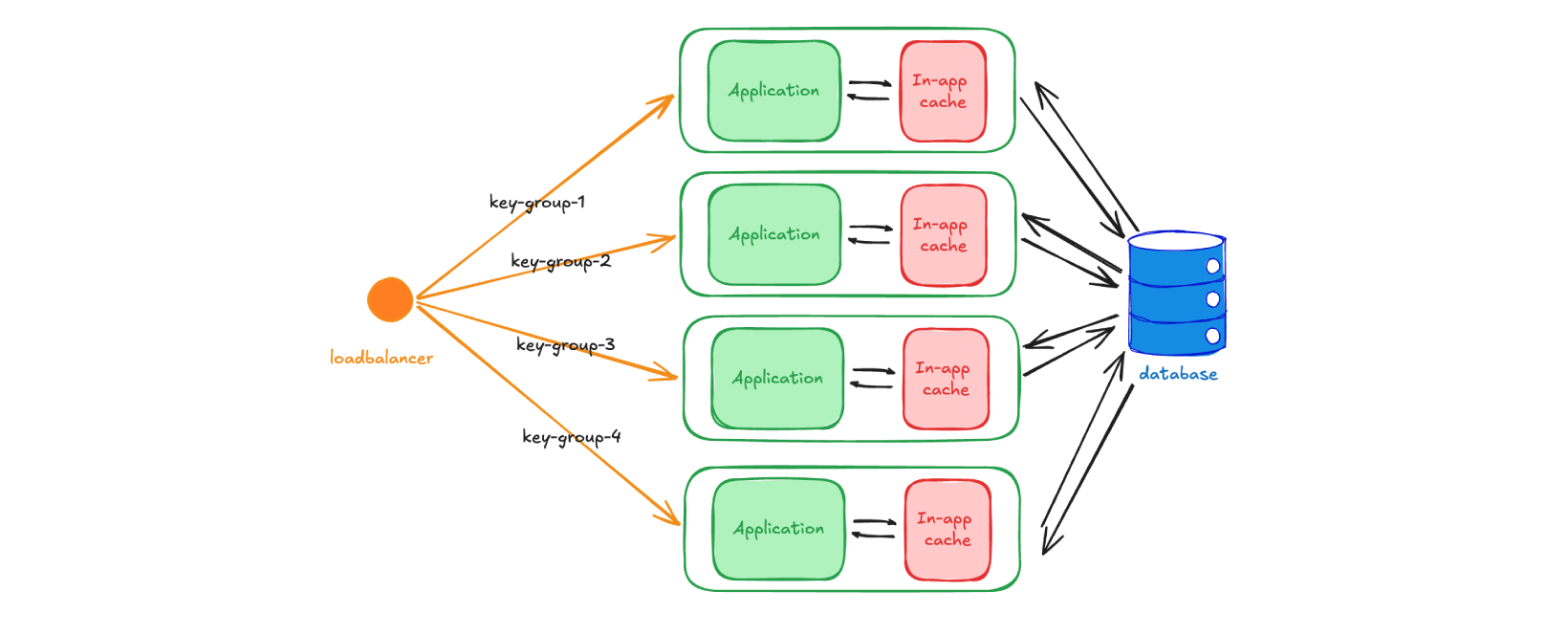
For example, maybe you have a multi-tenant system that serves 500 companies as “teams” in your app. You are very comfortable with having 5 hosts and can split the traffic at the load balancer level. Companies 1-100 go to host 1, 101-200 to host 2, and so on. In this scenario you can cache in memory and mostly avoid distributed cache invalidation, because the same tenant keeps landing on the same node. If no other host can modify the data you have cached, then you have much less reason to worry.
So, when does this fall apart? Let’s say you go 10x scale. 5000 companies = 50 hosts. This kind of scaling will become super expensive because you are keeping your hosts underutilized for the sake of cache simplicity. The trade-off is not worth it—you are making a complicated, expensive fleet of hosts, in order to avoid having an extra caching layer that is much simpler by comparison. Your failover response also becomes worse.
But, if your system is going to stay at that initial scale level for a very long time, and maybe never outgrow 5 hosts, this becomes a very appealing solution.
Case 3: Serverless / Lambda-style systems
Now to the most inflexible setup. Think: AWS Lambda, Vercel functions, or Cloudflare Workers. In these systems, instances are often short-lived, memory is not shared across instances, and cold starts reset everything.
This is effectively a worst-case environment for in-memory caching. It can still help a little inside a warm instance, but it is usually a weak primary cache strategy. Even so, you will still find blog posts saying well-meaning nonsense like “just cache in memory inside the function”. It technically works within a single execution or warm container, but in practice:
- it’s inconsistent
- it often doesn’t survive across executions
- it provides little real system-level benefit
I am sure it works in some cases—like bursty traffic that keeps hitting warm instances, or parallel Step Functions workflows that access similar state—but it’s not something you should rely on for correctness or consistent cache hit rates.
If caching matters here, it has to be external, but I have a feeling your solution will not be Redis. If you are in the serverless world of compute, I suspect you are also using serverless databases, like DynamoDB. These products have their own caching solutions that offer the same promise: “pay us a premium, and we offer you serverless simplicity.” DynamoDB’s DAX is a prime example. In March 2026, the price of a t3.medium DAX instance is $0.08/hr, while the same EC2 instance is $0.04/hr. You are paying double for the convenience. (I am not saying that is bad, mind you. But you should be aware of it, since you pay a similar tax on every single managed service you add.)
The industry has done a good job of convincing us that paying a premium is worth it, because it saves developer time, which is much more expensive. Now that these same companies are convincing us that LLMs will make developers obsolete, I wonder if the trend will reverse.
Anyway, the bottom line is that serverless sort of pushes you naturally towards certain solutions. Those solutions are correct and simple, but the cost can quickly add up.
Closing Thought
Caching is one of those areas where the simplest solution works longer than expected.
Redis is a great tool. Managed services like ElastiCache are reliable and well-designed. But they’re not the starting point for every system.
Start simple. Measure. Load test.
Move to something more complex only when the system forces you to.
Wishing you a low cache-miss rate,
–Filip