Jumping into a new project can be scary. Especially if “legacy” the words used to describe it. But if you learn the right techniques to navigating a new codebase then on-boarding will take a lot less time.
Over my 5+ year career I’ve had to switch between projects of various sizes. It’s been frustrating at times, but I’ve noticed certain patterns over the years.
This article is an evolving collection of techniques that I’ve developed to help me become as productive as possible. I recently joined Amazon and this methodology has proven its worth for me – allowing me to contribute since week 1!
Traversing Uncharted Territory

Let me set the scene. This is a short personal anecdote from 5 years ago that will be entertaining to read. It’s purpose is to show just how hard it can be to join a large codebase. (You can skip this part by clicking here.)
Part 1: Problem Setup
Ever read a murder mystery, but instead of solving a murder, the character is fixing a bug? Here’s the scenario for out little detective mystery:
🔎 Context: You’re working on a giant monolith app. The tech is somewhat outdated. (New questions stopped appearing on Stack Overflow around 2010.) There’s also little documentation left by the previous team.
📝 Task: The client reported a bug with one of the form components on the interface. We will henceforth call this Component A. The client is using Chrome on Windows 10.
😵 Confusion: Upon inspection in Chrome on Mac OS, you cannot reproduce the bug. You could also not replicate the bug on your virtual machine. (It works great both on Edge, Chrome, and IE11!)
💡 To clarify: The client is not making this up. You refer to their screenshots and also note that the form looks different on their end. (The styles don’t match.)
How do you tackle this? Working with bugs that are hard to reproduce is a hard time. What’s the thought process and where do you start looking first? Also, remember: you’re new to this large codebase.
Part 2: Initial Approach
I was lucky to have a colleague who uses Windows. I got them to open the staging app and check it out. And the bug was there in all its glory.
I found it strange that the bug was not present on VirtualBox. Was the version of Chrome on the VM different?
I borrowed their computer over lunch. Then, I inspected the generated HTML and JavaScript bundle via Chrome Developer Tools. My findings were surprising. This strange component was not our Component A.
Since the bundled code is obfuscated it was hard to figure out what I was looking at. But, I was able to eventually find this component. This Component B performed the same functionality but had different styles and behavior.
Knowing the name of the component I fixed the bug – that was related to the logic – and tested the changes. Sure enough, the component on the screen still had different styles, but the bug had been solved.
Part 3: Digging Deeper

Yay, bug solved, case closed, right? Well, not quite. This is an interesting find and it has to be resolved. Anything else would be dishonest to the client and disrespectful to my craft.
Some more context: These two components are date inputs. (Very specialized to the business process.) They achieve the same result in the end, but the input flows are very different. These components also look strikingly different in their visual style.
My suspicion was that there had to be some sort of if/else switch that determines when B is inserted instead of A.
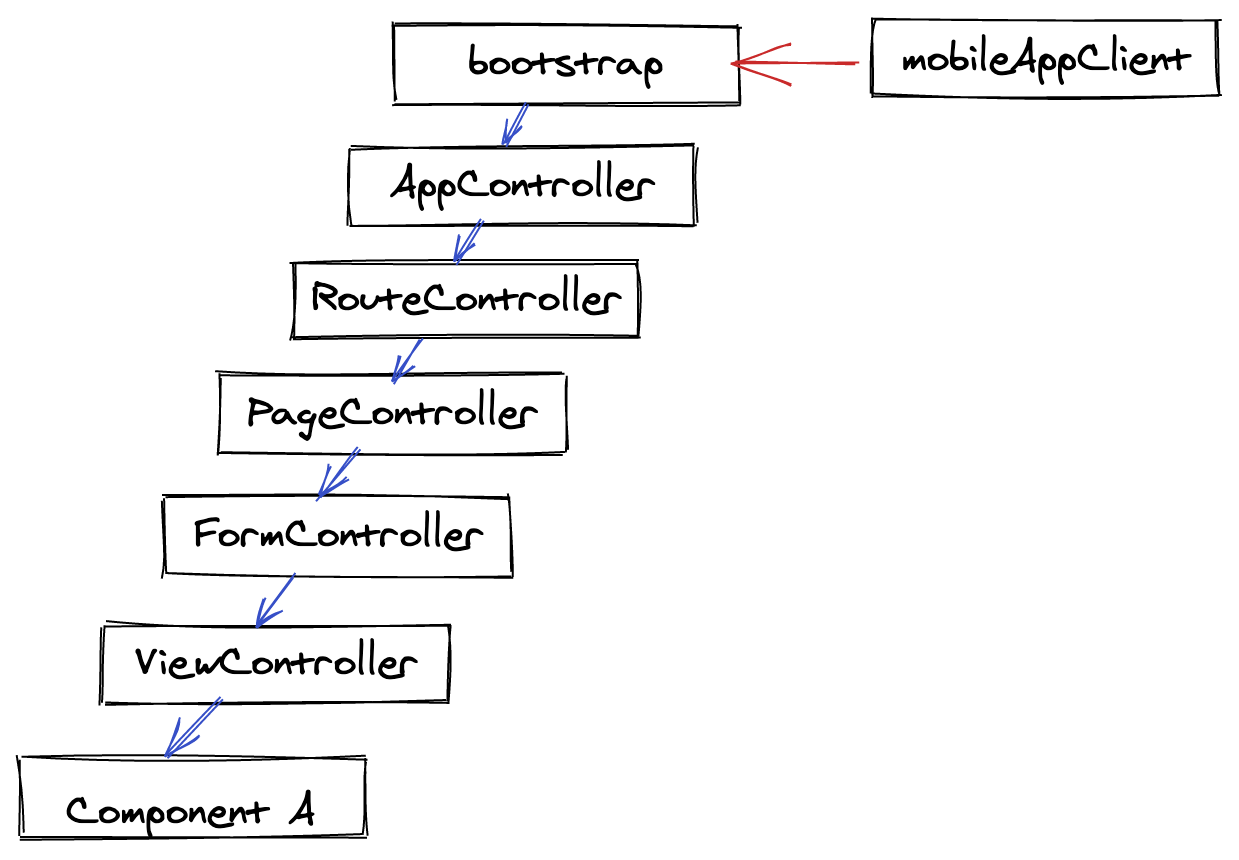
I started looking at the controller that instantiates the component and worked my way up.
I did not find any such logic on my way to the final file. This was a top-level “bootstrap” file that registers every component that’s used in the app. It imports these components and makes them available to the global namespace. It does this via a registerImplementation() method.
At this point, I am a bit fatigued. I had crawled my way up a big dependency graph, but have not found what I was looking for.
Rotten luck, so far.
Now, I’ve seen this “bootstrap” file before, but don’t remember seeing any real logic inside of it.
As expected I did not find any magical if/else statement. What I did find was a registerImplementation() call for Component A, but none for Component B.
I read the file line-by-line and towards the bottom of the file, I noticed something I missed earlier. There was a require statement for a file called mobileAppClient.
The Mystery Solved
In this file was a magical block of code:
if (app.getIsMobile()) {
overrideImplementation(componentA, componentB);
// …other code
}This was no doubt the problem. The app would use Component B over Component A on mobile devices. And I suspected that this magical getIsMobile() method was the problem. (Spoiler: Yes, yes it was!)
The implementation was naïve. Much like this:
function app.getIsMobile() {
return Modernizer.touchEvents;
}This logic treated every device with a touchscreen as a mobile device. Sure enough, my colleague’s laptop did have a touchscreen. And so did the client who reported the bug.
I reimplemented this method in a more sophisticated way and properly solved the bug. Hooray!
Grasping The Unfamiliar
The hunt for the source of this little bug took around 3 hours.
The business value was also greater than initially expected. This bugfix solved several other issues the client was having.
It also lead us to a bigger discussion about the app’s mobile experience. (Which was in poor state.)
As for me, this experience helped me get a better grasp of the entire system. As I encountered something new or unusual I’d take a note of it. I was writing a “traveler’s journal” of this unfamiliar codebase.
This is why hunting bugs in a large codebase you’re not familiar with can be summed up as: “Solving a (murder) mystery in an unfamiliar land.”
You first have to get your bearings, chart out the land, and then start gathering clues and cracking the case.
How to Dive Into a Large Codebase
First of all, understanding the codebase is something that is bound to happen eventually. But, if you’re expected to do it often then it helps to develop the techniques that make it easier.

But, if you have to do this on a regular basis, how can you get good (and fast!) at doing it? It comes down to a couple of techniques. I call them:
- Observing and researching,
- Testing,
- Digging,
- Breaking,
- Time traveling, and
- Resting
I know the names are not brilliant, but let’s see what they bring to the table.
Observing and Researching
The first thing you should do on a new project is to spend time using the app in a production environment. Get to know all the features and the business problems the app is solving.
The best way to go about this is exploratory testing.
This step is crucial to understanding the project. Especially if this is a business domain that you are unfamiliar with.
Get an On-boarding Buddy
Your time will be a lot easier if you find someone who has tenure in the project and is open to answering your question.
Don’t disregard engineers who might have much less experience than you. Anyone who has been around longer than you is a great source of knowledge. Project tenure is the most important metric.
It’s best for this person to be a fellow engineer. You can find a separate person who you can look up to as a domain expert.
Read the Docs
After that, you should do detailed research to find all the documentation that exists. (But, take the docs with a grain of salt as they are likely outdated.)
Here’s what you’re looking for (in order of importance):
- All the project README files. (Check when they were last updated.)
- A project wiki.
- Recent meeting notes (preferably with key stakeholders.)
- Architecture design docs.
- Deployment docs.
- Backlog of upcoming epics.
- Backlog of fixed issues.
- User interview reports, videos, etc.
- Mockups of upcoming features.
Improve the Docs
At a minimum there’s going be a README file for the project you just joined. This file will be outdated (I can bet on it!) and the instruction will likely be unclear.
Most devs write this file from their point of understanding – they already know how to start the system. The README is just a short set of important notes for them. This is why newcomers to the project always struggle to follow the instructions.
This means you have a great role to play. You are coming to the project with no prior understanding and you can (and must!) update everything as you go.
Read the Tests
I hope you’ve just joined a project that actually has tests. If so, tests are basically a form of documentation. You can figure out a lot about the project by looking at:
- The names of the test cases.
- The associated inputs and expected outputs.
- Modules with the most edge cases covered – usually the most critical ones.
- The way third-party services are mocked and integrated.
You don’t need to look too much into the implementation of the tests until it becomes relevant to your task.
Improve the Tests
Just like with docs, not every team treats their tests with a high standard. Improving tests by covering edge cases or uncovered lines is a great way to dig deep into a specific piece of code. It also benefits the project and makes for a good early contribution.
If the project doesn’t have any tests then implementing them might be hard for you as a newcomer. You’ll have to earn trust with your team and manager before leading a big initiative like that. (But if you have a green light to do it, take it right away!)
Digging
This series of techniques is out-of-scope for the purposes of this article. I will list the concepts and trust you to do your homework and research the things you’re not familiar with.
But, it mostly boils down to using a good editor or IDE and actually using the features that make that editor awesome.

I use JetBrains WebStorm. (Visual Studio Code is a fine, open-source alternative.) As for you, you should use whatever you like. But bear in mind that some features are a “must have”, especially when jumping into a large codebase.
I’d say that these features are:
go-todefinition,- intelligent code completion (“intellisense” and the like),
- structure pop-up,
- jump to deceleration,
- jump down the hierarchy,
- show usage,
- regex search,
- git integration (to quickly inspect file history), and
- linter integration.
These make it easy to navigate any project with speed. They also shine when dealing with a new codebase.
I would also note that using the search feature of your editor can be very powerful when all else fails. Remember to make your queries more precise with regular expressions and by filtering out directories and file types.
Breaking
Debuggers and profilers are your friends! These tools are as important as your editor. Spend time finding the best ones and getting to know them.
Top features I look for:
- breakpoints (duh),
- change code at runtime,
- jump to line,
- performance profiling,
- track scope stack, and
- access values/methods in scope.
It is not uncommon to have several tools that handle these instead of an all-in-one solution. Obviously, this depends on the language, the surrounding ecosystem, and tooling. (For example, you might use specialized tools like the React Inspector and Redux DevTools.)
Time Travel
This tip boils down to one simple truth: git is your friend!
Scenario: Let’s say you’re fixing a complex bug. You’ve found all the important blocks of code, but you have a hard time figuring out how to actually fix the problem. What now?
At this point, you’ll find yourself confused by something specific. This will likely be a block of code that was at some point introduced either as a bug fix or a feature.
Looking at the history of that file will help you better understand how and when this happened.
How you achieve this is up to you. Some prefer to use git from their CLI of choice. The obvious* commands here are:
git log -p -- path/to/filegit showgit diff
_*A not so obvious command would be something like `git bisect`. My friend Jovan wrote a quick intro for [the Spicefactory blog](https://spicefactory.co/blog/2016/08/26/spicycomic-3-git-bisect/) about this topic._
I prefer to the use the git tools built into my IDE. I find that they help save time overall and don’t require that you remember all the commands and options.
Choose your tools as you see fit. But remember that the end goal is to go back in time. This should be efficient and yield as much useful information as possible.
You’ll first look for the git message and diff. Then try to find something like this:
- The reference to the ticket (bug report or feature request) that was addressed by the commit(s).
- The pull request and any discussion thread that may have existed.
- The test cases that were introduced/modified when the code was introduced.
And (this is somewhat my “favorite”):
The rapid “hotfixes” that were merged to “fix minor bugs”. These bugs appeared along with the feature.
Not sure what I mean? Tell me if this sounds familiar:
On smaller teams where one individual owns too much of the codebase, you will see these things happen. The developer will commit a major change (new feature). The feature will generally work but soon a set of bug reports comes in from the QA team or stakeholders.
In a race against time to complete their sprint, the developer will then introduce a series of rapid “fixes.”
These fixes never address the core problem. They instead introduce a solution to cover some edge-cases. If you’re ever in a situation like this one, consider this:
- Revert their bug fixes.
- Try to refactor.
- If the refactor fails, re-implement the feature from scratch.
This will likely take a lot more time. Communicate what you plan on doing to your project manager and see if it’s alright to commit that time.
Resting
My final tip is this: don’t overwork yourself and do everything to avoid burnout.

Programming is overwhelming.
New codebases (especially large ones!) are overwhelming. Trying to understand dozens of design decisions from the past is overwhelming.
Are you a junior developer? Then all the new patterns and needless clever abstractions you encounter will probably be overwhelming.
So with that in mind don’t make things harder for yourself.
Give yourself time to breathe. Don’t lose sleep over this. Fight your managers if they try to put you in a crunch or assign impossible-to-hit deadlines.
Final Takeaways
Fatigued by the article or just skipped ahead to see the titles and images? I feel you. Here’s what you should remember:
- Do your homework: Learn as much as you can about the domain, the business problems, the app architecture, and find all the docs you can.
- Gear up: Use a great IDE/Code editor that will make digging through the code easier.
- Debug at runtime: Set breakpoints at critical sections. Monitor the stack. Follow what’s happening line-by-line.
- Use git history: Remember to look at how a piece of code has changed over time whenever you are confused as to what it actually does. (Or why it even exists.)
- Rest and don’t be overwhelmed: Programming is hard. Your job is hard. Don’t make it harder by being tired and stressed.